Pro klienty hledám řešení technických nedostatků, které ovlivňují viditelnost webu ve vyhledávačích. Přesto jsem si ráda zašla na školení technického SEO. Těmito slovy začínal můj původní článek z února 2018, kdy jsem navštívila školení Technické SEO (nejen) pro vývojáře od Pavla Ungra a Jardy Hlavinky. Nyní, o sedm let později, je čas se k těmto poznámkám vrátit a doplnit je o aktuální know-how roku 2025. Co zůstává pravdou a co se změnilo? Jaké nové výzvy a trendy technické SEO přináší a co se naopak nemění?
Tento aktualizovaný průvodce kombinuje mé původní dojmy ze školení s nejnovějšími poznatky. Je určen SEO konzultantům i dalším nadšencům do vyhledávačů, kteří chtějí udržet krok s dobou. Připravte se na směs osobních zkušeností a odborných tipů – lidským tónem, ale s přesností.
Článek jsem napsala v únoru 19. 2. 2018 a aktualizovala 28. 5. 2025
Školení technického SEO (nejen) pro vývojáře od zkušených matadorů Pavla Ungra a Jardy Hlavinky (Jarda působí v Seznam.cz) bylo v roce 2018 komplexní a informačně nabité. Doporučila jsem ho tehdy všem vývojářům i SEO konzultantům, kteří chtěli najít společnou řeč nad „nekonečnými“ weby a jejich technickými úskalími. Dnes bych to doporučení klidně zopakovala – základy zůstávají platné, a kdo má možnost se od Pavla či Jardy učit, neprohloupí.
Proč školení vlastně vzniklo? Pavel tehdy prohlásil:
„Konzultanti nadávají na vývojáře. Vývojáři nadávají na konzultanty. Všichni mají v zásadě pravdu. Musíme se navzájem snažit pochopit.“
A přesně v tomto duchu se neslo celé školení – jako most mezi světy kódu a marketingu.
Užijte si tedy pár poznámek ze školení s rozšířeným komentářem k roku 2025. Původní osnovu ponechávám, doplním však aktuální informace – od novinek Google a Seznamu přes Core Web Vitals až po IndexNow či logy serveru.
Pavel Ungr a Jarda Hlavinka představují harmonogram kurzu Technické SEO nejen pro vývojáře
Rozcvička na začátek
Pavel s Jardou na úvod v roce 2018 rozebrali tehdejší pohled na SEO a problémy, které řešíme. Už tehdy platilo, že mnohdy ani nemusíme chodit „ven“ z Googlu – odpověď na náš dotaz často najdeme přímo na stránce výsledků (SERP).
Vyhledávače nabízely stále více rozšířených výsledků (SERP features): placené inzeráty, boxy s nákupy, Mapy Google, rich snippety, odpovědní boxy apod. EO údajně „zabilo“ (not provided) v Google Analytics – narážka na skutečnost, že optimalizace už dávno není jen o pozicích a klíčových slovech.
SEO rozhodně není mrtvé, jak se občas uvádí. Ani podvod na lidi.
Tehdy se někdy ozývaly hlasy, že SEO je mrtvé (případně „podvod na lidi“). Opak je pravdou – SEO rozhodně mrtvé není. Jen se neustále proměňuje a stává komplexnějším.
V roce 2018 jsme mohli mluvit o strojovém učení ve vyhledávání, konkrétně o Google RankBrain – systému, který na základě chování uživatelů pomáhal přepisovat výsledky v SERPu a ovlivňovat jejich pořadí.
RankBrain byl jedním z prvních větších AI prvků v Googlu a dostal se mezi tři nejdůležitější faktory SEO 2018 (vedle obsahu a odkazů).
2018 vs. 2025: Co se změnilo?
Když se nad tím zamyslím, co by dnes lektoři zmínili jako hlavní trendy?
Obsah a kvalitní zpětné odkazy zůstávají králové. Google však svůj algoritmus od dob RankBrain výrazně posunul – přišly modely jako BERT (porozumění přirozenému jazyku), MUM (multimodální AI) a další.
Vyhledávání se také přesouvá k mobilům (dnes už je indexace mobile-first standardem) a na obzoru je éra AI ve vyhledávání. Google i Microsoft (Bing) experimentují s generativním vyhledáváním, tedy vyhledáváním, kde odpověď generuje AI přímo ve výsledcích. Uživatel tak může dostat komplexní odpověď bez prokliku na web.
Co to znamená? Že SEO se musí adaptovat. Důraz na E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) při tvorbě obsahu je větší než kdy dřív. Z technického hlediska pak musíme myslet nejen na Googlebot, ale i na různé AI crawlery, které berou obsah pro trénink modelů či generování odpovědí.
V roce 2023 oznámil OpenAI svého GPTBot a umožnil webmasterům jej zablokovat, aby jejich data nesloužila k trénování ChatGPT.
Jedno ovšem platí stejně v roce 2025 jako 2018: technické SEO máme pod kontrolou – a právě proto je tak důležité. Mnoho jiných věcí (jak se bude chovat uživatel, co udělá konkurence, jaké algoritmické finty nasadí Google) neovlivníme.
Ale to, jak náš web funguje po technické stránce, v rukou máme. Pojďme se tedy podívat na technické základy i novinky, ať nás nic nezaskočí.
Technické SEO máme pod kontrolou
Tohle heslo zaznělo na školení a dodnes s ním souhlasím.
Technické řešení webu je totiž jedna z mála oblastí SEO, kterou můžeme přímo ovlivnit. Obsah nám někdo může zkopírovat (a tím vytvořit duplicity), odkazy samy nezískáme (linkbuilding není raketová věda, ale vyžaduje praxi a čas).
Navíc uživatelské signály a AI typu RankBrain/MUM mohou s pořadím v SERPu zamíchat podle toho, na co lidi klikají. Nemůžeme si tak být jisti ničím – kromě toho, jak si vedeme po technické stránce.
Máte-li zkušeného a trpělivého vývojáře, který naslouchá a nepokládá SEO konzultanty za šarlatány, máte napůl vyhráno. 🙂 Společně můžete zajistit, že váš web bude pro vyhledávače perfektně přístupný, rychlý a bez technických chyb. To je pevný základ, na kterém teprve může obsah a autorita stavět.
Technické pasti na nepřipravené
Pojďme k samotnému školení a jeho tématům. První blok byl věnován indexaci, tedy tomu, jak dostat stránky do vyhledávačů a udržet je tam. V této části budu průběžně doplňovat současné poznatky k tomu, co zaznělo v roce 2018.
Indexace
Crawling vs. indexace
Je dobré si ujasnit pojmy: crawling (procházení) znamená, že robot (crawler) se snaží stáhnout obsah stránky. Indexace pak označuje proces, kdy indexer uloží stránku do databáze vyhledávače a zařadí ji mezi výsledky v SERPu (search index). Crawlování ještě neznamená, že stránka bude indexována – robot ji může navštívit, ale indexer se rozhodne obsah nezařadit.
Na školení zaznělo, že mezi Googlem a Seznamem existují rozdíly.
Google funguje víceméně přímočaře: zjistí URL (např. z odkazů nebo sitemap), přijde na stránku, stáhne obsah a vyhodnotí, zda ho zařadí do indexu.
Seznam.cz tehdy (2018) přistupoval trochu jinak: přijde na stránku a už při stahování se rozhoduje, jestli má smysl data vůbec načítat. Kvůli úspoře výkonu může Seznam některé stránky ani nestáhnout – typicky když uvidí, že je stránka prázdná nebo obsahuje jen bezcenný text typu lorem ipsum. Nemá důvod takovou stránku plýtvat kapacitu.
Není to tím, že by byl Seznam „pomalý“, jen prostě vyhodnocuje předem, zda mu stránka stojí za námahu. Pokud ne, nestáhne ji a samozřejmě ji pak nezaindexuje. Google naopak stáhne skoro vše (až pak vyřadí balast v indexu dodatečně).
Musím ale dodat, že od té doby Seznam svůj vyhledávač modernizoval a také kapacity rostly. I tak však platí, že Google má v indexaci náskok – nejen technologický, ale i co do přístupu. Ostatně tržní podíl Google v ČR je stále celkem stabilní (k dubnu 2025 cca 81 % Google vs. 12 % Seznam).
Seznam si nemůže dovolit plýtvat zdroji na zbytečnosti, takže buďme rádi, když naše stránky shledá hned na první dobrou hodnými stažení a indexace.
Velmi důležité je chápat rozdíl mezi zákazem procházení a zákazem indexace. Tyto pojmy se pletou, přitom jsou zcela odlišné:
Zákaz procházení (crawl): říká robotovi, aby na stránku nechodil. Dosáhneme ho v souboru robots.txt pomocí direktivy Disallow. Pokud je něco disallow, robot to (většinou) nebude stahovat. Nezjistí tedy obsah stránky. Například zakážu-li v robots.txt /secret/, vyhledávač dovnitř nepoleze (Googlebot i SeznamBot zákaz obvykle respektují).
Zákaz indexace: říká vyhledávači, aby stránku nezařazoval do indexu (a neukazoval ji ve výsledcích). Provádí se to většinou meta tagem <meta name=“robots“ content=“noindex“> v HTML hlavičce stránky, případně HTTP hlavičkou X-Robots-Tag: noindex. Robot stránku prochází (musí ji stáhnout, aby ten meta tag našel), ale pak ji vyřadí z indexu.
Je vidět, že to nelze zaměňovat. Častá chyba je myslet si, že robots.txt zákaz indexace – tak to není. robots.txt nezná příkaz „noindex“.
Pokud zablokuju stránku v robots.txt, Google ji sice neproleze, ale teoreticky ji může do indexu dát i tak, pokud na ni vedou externí odkazy a vyhledávač usoudí, že o ní něco ví. (Typicky by ji pak v indexu měl jen s URL a bez popisku, protože obsah nečetl.)
Ke spolehlivému zákazu indexace vždy použijte noindex (meta nebo X-Robots). Ideálně zkombinujte s tím, že stránka stejně není důležitá a neodkazujete na ni.
Aktualita 2019: Google dříve tiše toleroval trik, že se do robots.txt napsalo Noindex: /sekce/ a on to respektoval. Ale v září 2019 podporu tohoto neoficiálníhodirektivního hacku zcela ukončil. Takže už se na to nelze spoléhat vůbec. Pokud chcete stránku vyřadit z indexu Google, musíte povolit crawling a dát tam noindex. (A nebo použít nástroj pro odebrání v Search Console dočasně.)
Shrnutí:Robots.txt = nástroj na řízení crawlingu. noindex (meta či hlavička) = nástroj na řízení indexace. A pozor – když něco zakážete v robots.txt, už tam nedostanete meta noindex (protože se na stránku robot nedostane, aby ho přečetl). Tyto metody se navzájem vylučují.
Kodex „dobré indexace“
Líbil se mi termín Kodex dobré indexace, který lektoři představili. Šlo o srozumitelně popsaná základní pravidla, jak dostat stránky do vyhledávačů. Dovolím si je zde zrekapitulovat a okomentovat z pohledu 2025:
I. Poskytujte vyhledávačům své URL:
Odkazy – Vedou na vaše stránky odkazy z významných a již indexovaných stránek? (Když nový web vůbec nemá odkazy z internetu, vyhledávače ho nemusí objevit dlouho. Platí stále – externí odkazy či sdílení urychlí objevení nového obsahu.)
Sitemap.xml – Máte URL v sitemap.xml? A odkaz na sitemap v robots.txt? (Dodnes best practice. Správně generovaná XML sitemap usnadňuje vyhledávačům najít všechny důležité stránky.)
Search Console / Webmaster tools – Přidali jste svůj web do Google Search Console a případně Bing Webmaster Tools či Seznam Webmaster? (Google Search Console je nutnost – nejen že tam můžete nahrát sitemap, ale získáte tím i přehled o indexaci a případných chybách.)
Ruční přidání přes formulář – (Tohle je z roku 2018.) Existovaly formuláře pro ruční přidání URL:
Seznam: formulář Přidej stránku (ten stále existuje, najdete ho na search.seznam.cz – viz Nástroje pro webmastery, Přidání URL).
Google: býval veřejný formulář Submit URL (ten už byl ale zrušen; dnes jediná cesta je přes GSC funkcionalitu „Požádat o indexování“ u konkrétní URL).
Bing: podobně lze přidat URL v Bing Webmaster Tools, ale u Bingu stojí za zmínku spíš novinka IndexNow – o té níže.
II. Dávejte vyhledávačům důvody k indexaci:
Nepředkládejte duplicitní či prázdný obsah – Vyhledávače nemají rády duplicity a bezcenný obsah. (Platilo a platí. Pokud robot zjistí, že stránka je jen kopie jiné nebo má minimální hodnotu – třeba placeholder – možná ji ani nezařadí.)
Dobrý obsah od počátku – Tip ze školení: Můžete vyhledávače odradit hned při první návštěvě. (Např. spustit poloprázdný web „ve výstavbě“ – robot přijde, nic moc tam není, a pak se dlouho nevrací. Lepší je spustit web až když má aspoň základní obsah připravený.)
Pokud máte nějaké stránky nevhodné pro index (např. nekonečné varianty parametrů), označte odkazy na ně atributem rel=“nofollow“. (To byl tip, jak zamezit prolézání nepotřebných odkazů. Nofollow Google i Seznam respektují – dnes se tedy spíš říká, že je to „pouze náznak“, ale v praxi vyhledávače nofollow odkazy skutečně neprolézají.)
III. Nevytvářejte překážky v crawlování/indexaci:
Zde padlo hned několik bodů – zrádné jsou různé technické chyby:
Matoucí přesměrování – např. zacyklené nebo zbytečně komplikované:
I kanonizace je přesměrování (byť jen jako doporučení). (Tím chtěli říct, že použitím <link rel=“canonical“> vlastně říkáte „místo této stránky preferuji jinou“ – funguje to podobně jako přesměrování, jen méně silně.)
Struktura přesměrování se často mění. (Tzn. nezakládat na tom složité strategie – co jde, přesměrovat jednoduše.)
Násobná přesměrování (redirect chain) – čím delší řetěz, tím hůř.
Příliš mnoho stránek – Vyhledávače mají omezenou rychlost procházení (tzv. crawl rate limit). Třeba WordPress.com v roce 2018 pouštěl Googlebota jen 1 stránku za 2 sekundy. Také pokud má váš server pomalou odezvu, roboti uberou. (Dodnes Google reguluje crawling podle výkonu serveru – když vidí pomalé reakce nebo chyby, zpomalí a sníží zátěž.)
Funkční web, který nezlobí – Předcházejte častým chybám:
„3x a dost“ – pokud robot opakovaně narazí na technické chyby (např. 500 Internal Server Error), může stránku na delší dobu vynechat. Něco ve smyslu: když web 3x po sobě neodpovídá, Google si dá pauzu. Proto hlídejte uptime a chyby.
Penalizace – když web porušuje pravidla (o penalizacích více níže), může být vyřazen či omezen. To je extrémní překážka, kterou si způsobíte sami černým SEO.
Neblbněte s JavaScriptem – např. location.href – tím naráželi na různé JS triky. Třeba přesměrování pomocí window.location namísto serverového redirectu. Vyhledávače taková přesměrování obvykle poznají, ale je to nespolehlivé a zbytečné; doporučuje se vždy preferovat serverový redirect nad JS nebo meta refresh.
Novinka 2025: K bodu 1 – přesměrování a řetězce. Google dříve deklaroval, že násobné přesměrování se mu nelíbí a zhruba po 5 hopech končí. Dnes oficiálně uvádí, že Googlebot sleduje až 10 přesměrování v řetězu. V praxi sleduje 5 hopů v jedné návštěvě a pokud je řetěz delší, při dalším crawl session naváže až do celkových 10.
Více než 10 hopů už Google neindexuje – v Google Search Console byste viděli chybu „Příliš mnoho přesměrování“. To ale neznamená, že by řetězce byly OK. Jsou plýtváním crawl budgetu a zpomalují načtení stránky pro uživatele. Stále tedy platí: udržujte přesměrování co nejkratší (ideálně rovnou z URL A na URL B). Řetězce delší než 3–5 přesměrování už řešte.
A hlavně se vyhněte smyčkám (redirect loop), kdy URL1 → URL2 → zase URL1. To zmate boty i uživatele a může vám to server zahltit, jak se robot chytí do nekonečna.
Co se indexuje a neindexuje
Na scénu ve školení tenkrát nastoupil Jarda Hlavinka a rozebíral jednotlivé prvky, které se indexují, a které ne, v Google vs. Seznam. Proběhla samozřejmě diskuze na věčné téma indexace skrytého textu (typicky záložky, accordiony).
V roce 2018 platilo pravidlo: na desktopu musí být text viditelný, jinak nemusí být indexován. Na mobilu se tolerovalo, že část obsahu je skryta (kvůli UX omezenému prostoru) – Google to nevadilo, Seznam tuším také ne. Tehdy se totiž přecházelo na mobile-first indexing, ale ještě to nebyl standard pro všechny weby.
Dnes (2025) už můžeme říct jasně: Google indexuje i obsah schovaný v tabech/accordionech – pokud je přítomen v HTML kódu. S plným přechodem na mobile-first (Google indexuje mobilní verzi stránek) bere v potaz i text, který je defaultně schovaný za záložkou, protože chápe, že na mobilu jde o zlepšení UX, ne o spam.
Google už v roce 2016 ústy Garyho Illyese potvrdil, že „v mobilním světě má obsah skrytý kvůli UX plnou váhu“. John Mueller to pak opakovaně potvrdil, např. v Google Webmaster Hangoutu 2020 řekl: „Pokud jde o obsah na mobilních stránkách, bereme v úvahu cokoliv v HTML. Když tam něco je – i když to vidí uživatel až po interakci – zahrneme to do indexu. To je úplně normální.“
Důležité: Toto však platí pro případy, kdy je obsah skutečně v HTML. Pokud by byl obsah načtený až po kliknutí přes JavaScript (např. voláním na server), robot ho neuvidí, protože ten klik neprovede. Takže obsah za záložkami vždy generujte do HTML stránky (jen ho schovejte CSS/JS). Pak není problém. Když by byl obsah načten až dynamicky, musíte zajistit buď server-side rendering nebo aspoň použít state v URL, aby se to dalo indexovat samostatně.
Seznam.cz v tomto ohledu historicky byl přísnější na „co je rovnou vidět“. Je otázka, jak dnes, bohužel nevím oficiální vyjádření. Pravděpodobně ale také indexuje to, co v HTML je (i když skryté přes CSS), protože i Seznam přešel na indexaci renderovaného obsahu (má vlastní rendering engine).
Každopádně platí: nesnažte se schovávat nic důležitého záměrně před uživatelem, to vám nepomůže.
Vyhledávače to poznají (třeba text stejnou barvou jako pozadí = jistá penalizace). Ale pro přehlednost obsahu klidně použijte accordiony, záložky, “číst dál” – vyhledávače to chápou a indexují.
Co se indexuje / neindexuje?
Další témata z technického školení
Po probrání indexace jsme se na kurzu vrhli i na další technická témata. Mnohé z toho jsou nadčasové rady – a některé si žádají aktualizaci, protože vývoj jde kupředu. Pojďme je projít:
Sitemap.xml
Další velké téma byl soubor sitemap.xml. Probrali jsme, jaké typy sitemap existují (pro URL adresy, pro videa, obrázky, zpravodajství…) a jaké mají limity – maximální velikost souboru (10 MB nekomprimovaně), maximálně 50 tisíc URL v jedné sitemap atd.
Zaznělo, že do sitemap patří jen důležité URL s kódem 200. Rozhodně tam nepatří stránky vracející 4xx, 5xx ani ty, co přesměrovávají (3xx). Pozor i na URL zakázané v robots.txt nebo opatřené noindex či kanonizované – ty taky do sitemap nedáváme. Chceme v ní mít prostě seznam cílových, kanonických adres, které mají být indexovány.
U jazykových mutací – každá URL mutace by měla být v sitemap samostatně. Parametrické stránky (např. filtry), pokud jsou důležité pro index, tam taky můžeme uvést. Dokonce URL v sitemap mohou být cross-domain, takže lze mít centralizovanou sitemap pro více domén (typicky u mutací v různých ccTLD). To je spíš zajímavost, běžně se nevyužije.
Co je nového kolem sitemap v 2025? Pravidla se v zásadě nezměnila, ale Google i Bing začali klást větší důraz na atribut <lastmod> – datum poslední změny stránky. Zatímco dříve Google říkal, že lastmod často ignoruje (protože byl zneužíván či nepřesný), dnes uvádí, že „lastmod je užitečný v mnoha případech a používáme ho jako signál pro načasování re-crawlu dříve objevených URL“
Musí ale být věrohodný: pokud stránku aktualizujete jednou za rok, nepište tam každý den včerejší datum, Google vám přestane věřit.
Doporučení Google zní: uvádějte lastmod tam, kde dokážete opravdu udržovat jeho správnost (klidně třeba jen u článků, produktů – a vynechte ho u stránek, kde by to bylo složité jako rubriky apod.).
A hlavně: „lastmod“ znamená datum poslední významné změny obsahu. Neaktualizujte ho kvůli každé drobnosti v šabloně, ale když fakt změníte text, přidáte sekci, upravíte strukturovaná data atd., pak ano.
Google také v roce 2023 zrušil svůj vlastní endpoint na pingování sitemapy (byl to URL google.com/ping?sitemap=…), protože drtivá většina využití byly spamy a nepřinášelo to hodnotu. Nově stačí mít sitemapu v robots.txt a případně ji nahrát v GSC – Google si změn všimne sám. Bing ponechal svoje pingy, ale s příchodem IndexNow (viz níže) to také není kritické.
Ještě jedna významná novinka: IndexNow protokol. Ten sice nesouvisí přímo se sitemap.xml, ale je to alternativní či doplňkový způsob, jak aktivně poslat vyhledávačům signál o změně na webu. IndexNow zavedl Bing a Yandex v roce 2021 a dnes (2025) ho podporují i další – např. Seznam.cz a Naver.
Funguje to tak, že když přidáte, změníte nebo smažete stránku, vyšlete požadavek na API (ping) s URL a vyhledávač si ji přijde hned procházet.
Výhodou je, že zúčastnění vyhledávači si tyto signály sdílejí – stačí pingnout třeba Bing a ten URL předá i Seznamu, Yandexu atd. IndexNow si získal slušnou adopci: koncem 2023 ho užívalo přes 60 milionů webů, posílalo ~1,4 miliardy URL denně, a Bing v roce 2024 hlásil, že 17 % nově objevovaných URL získává právě přes IndexNow.
Google se k IndexNow zatím jen „dívá z povzdálí“ a nepřidal se (i když testoval), takže pro Google nadále platí klasika – crawling dle vlastního uvážení. Pro Bing, Seznam apod. ale může IndexNow výrazně zrychlit indexaci novinek.
Pro nás z toho plyne: zvažte nasazení IndexNow, pokud spravujete velký web často se měnící (např. e-commerce s častými změnami produktů). Není to složité – vygeneruje se klíč a pinguje se API (existují na to i pluginy). Neznamená to, že nemusíte mít sitemap – spíš je to další kanál, jak poslat vyhledávačům informace.
Neindexace URL
Na školení se hodně řešily důvody a řešení, proč některé URL neindexovat. Obecně platí: do indexu chceme jen kvalitní, důležité a unikátní stránky. Nechceme indexovat to, co je duplicitní, nekvalitní, nebo bezvýznamné.
Typické příklady: různé stránkování, nekonečné kombinace filtrů v e-shopu, parametrové varianty stránek (řazení, trackovací parametry). To všechno může generovat tisíce URL navíc, které uživateli nepřinášejí nové hodnotné info, a vyhledávač by jimi jen plýtval kapacitu.
Kluci shrnuli možná řešení: buď takové stránky vůbec nevytvářet (např. vyhnout se generování samostatné URL pro každé řazení), nebo je zablokovat/označit pro neindexaci:
Do sitemap posílat jen důležité URL.
Duplicity řešit pomocí kanonických odkazů (viz dále).
Nepodstatné varianty opatřit noindex (pokud je potřebujeme pro uživatele, ale nechceme je v indexu).
Nebo je úplně odstřihnout pro roboty (noindex + navíc ani neodkazovat interně, případně Disallow – ale tam pozor, ať se pak neindexují, viz výše).
Velký důraz byl kladen na správnou strukturu URL. U některých e-shopů se můžete na tentýž produkt dostat několika cestami (např. různé kategoriové cesty v URL) a vznikají tak duplicitní stránky. Je potřeba to ošetřit – buď sjednotit URL strukturu (aby produkt měl jedno kanonické URL), nebo použít kanonické linky či přesměrování. Duplicitní vstupní stránky jsou zlo – tříští PageRank i pozice.
V roce 2018 ještě existoval v Google Search Console Nástroj pro parametry URL – tam se dalo nastavit, co který parametr dělá (stránkování, filtrování…) a Google podle toho omezoval crawling. Pozor, v roce 2022 Google tento nástroj zrušil. Uvedl, že jen 1 % nastavení v něm bylo k užitku a že Google už „je mnohem lepší v hádání, které parametry jsou užitečné a které zbytečné“, proto jej označil za málo přínosný a vypnul.
Nyní se tedy musíme spolehnout na samotné weby, že budou parametry spravovat chytře.
Pokud víte, že určité kombinace filtrů nemají být indexované, musíte to zajistit na své straně – např. je neodkazovat, používat noindex na takových stránkách, případně je blokovat přes robots (ale pak raději ani neodkazovat, ať je robot neřeší vůbec). Google dnes tvrdí, že si většinou dokáže domyslet, co je „užitečná“ URL a co ne – ale spoléhat jen na to se nemusí vyplatit. Radši buďte proaktivní v řízení indexace parametrických stránek.
Seznam.cz žádný takový nástroj nikdy neměl, tam to vždy bylo na nás. Takže tady se situace vlastně sjednotila: vše je opět v našich rukou (což podporuje motto, že technické SEO máme pod kontrolou 🙂).
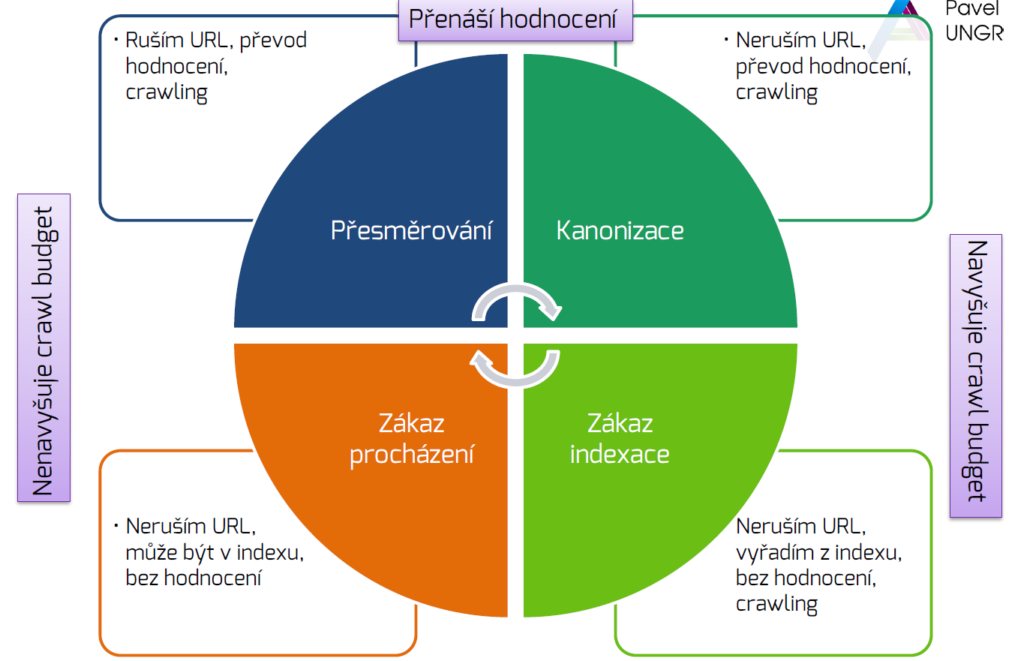
Přesměrování a kanonizace
Kdy použít přesměrování a kdy kanonizaci? To je evergreen. Zaznělo na školení pěkné zjednodušení:
301/302 přesměrování: původní URL po nasazení redirectu přestává existovat pro roboty i uživatele. Je to radikální a rychlý krok. Hodnocení (PageRank) se z velké části přesune na nový URL (Google už od roku 2016 tvrdí, že 301 ani 302 neztrácejí PageRank, prakticky je to totéž, jen 302 může být brána jako dočasná). Každopádně po redirectu se návštěvník i robot ocitnou jinde.
Kanonická URL (canonical link): původní URL stále existuje (není přesměrovaná), ale v HTML má <link rel=“canonical“ href=“…“> na nějakou jinou (kanonickou) adresu. Tím doporučujeme vyhledávači, aby tu původní neindexoval a místo ní preferoval tu kanonickou. Robot na původní stále může chodit, tím pádem nám zmenšuje crawl budget, a přestože by neměl být indexován, nějakou kapacitu to bere. I u kanonizace se hodnocení přesouvá (Google ji bere v potaz podobně jako kdyby to bylo sloučení stránek).
Z toho plyne: Pokud opravdu stránku ruším nebo přesouvám, raději přesměrujte (ideálně 301, ne 302, máte-li to nastálo). Kanonizaci používejte spíše u variant, které chcete udržet funkční, ale nechcete je indexovat (např. tiskovou verzi stránky, kterou necháte dostupnou, ale kanonizujete na normální verzi).
Na školení radili: když přesměrováváte trvale, volte 301 raději než 302 – to je jasné. A počítejte s dočasným propadem výkonu při velkých přesunech. Vždy záleží na autoritě webu a počtu přesměrování, ale obecně při přesměrování velkého množství URL může dočasně spadnout návštěvnost/ranking, než se to usadí.
Také padl tip: Po přesměrování nezapomeňte aktualizovat sitemap.xml a poslat ji do Google Search Console. To stále platí – když migrujete web, nahrajte novou sitemap do GSC (a ideálně i do Bing Webmastrs). Pomůže to rychlejšímu zpracování.
Z praxe dodám: přesměrování by ideálně nemělo chainovat (viz výše). Např. když měníte HTTP na HTTPS a zároveň doménu, udělejte rovnou redirect z starého HTTP na nový HTTPS, ne to lámat přes mezikroky. Google sice zvládne až 10 skoků, ale proč ho testovat. Každý hop navíc = risk ztráty signálu (i když malý) a zdržení.
A ještě jedna aktuální věc – v září 2023 Google oznámil podporu meta tagu indexifembedded. Ten řeší specifický problém: když máte stránku označenou noindex, tak se nikdy nemá indexovat samostatně – ale třeba může být vložená v rámci jiné stránky (iframe/embed). indexifembedded umožní Googlu indexovat obsah té stránky jen pro účely embedu jinde. Je to okrajová záležitost (např. pro embedované recenze, widgety), ale zmíním ji pro úplnost technické výbavy SEO konzultanta.
Přesměrování nebo kanonizace. Co použít? Malá ochutnávka ze školení
Stránkování
Stránkování (pagination) je na první pohled jasná věc, ale z pohledu SEO umí potrápit. Pokud máte e-shop s stránkovaným výpisem kategorie, chcete v ideálním případě, aby lidé přicházeli z vyhledávače hlavně na stránku 1 dané kategorie. Stránky 2,3,… nejsou moc užitečné vstupy (většinou obsahují jen další produkty).
V roce 2018 se řešilo, že pro Google existovalo elegantní řešení: použít dvojici tagů <link rel=“prev“> a <link rel=“next“> na stránkách v stránkované sérii. Ty mu napovídaly vztahy mezi stránkami a Google je uměl využít tak, že kumuloval signály napříč stránkami a často v SERPu zobrazil jen tu první (chápal je jako jeden celek). Problém: Seznam.cz tyto tagy nepodporoval. Takže co s tím?
Kluci radili: Cílem je, aby v indexu byla jen první stránka kategorie. Ty ostatní by se měly procházet (kvůli odkazům na další produkty), ale neměly by být indexované.
Zároveň by měly předávat link juice dál po webu (takže by neměly být úplně odstřižené). Řešení: dát na stránky 2+ meta tag noindex, follow.
Tím říkáme: „neindexuj tuto stránku, ale následuj odkazy na ní“. Výsledek: Google i Seznam stránku projdou, podívají se na odkazy (na produkty, další stránky), ale sami ji do indexu nezařadí.
Tohle řešení používá dodnes řada e-shopů. Google ovšem v roce 2019 všechny překvapil oznámením, že už delší dobu tagy prev/next ignoruje a stránky stránkování bere každou samostatně. Prostě změna plánu – žádné spojování.
Takže dnes oficiální stanovisko Google: žádný speciální tag na stránkování nepotřebujete, dělejte to hlavně pro uživatele. Doporučují klidně i neindexovat další stránky, pokud to dává smysl (což dává, protože nechcete, aby uživatel z Googlu spadl na str. 8 kategorie).
Takže přístup s noindex,follow na stránkách 2+ je validní i pro Google. Někteří odborníci sice namítají, že noindex,follow může vést k tomu, že Google časem přestane ty stránky navštěvovat (protože je dlouhodobě neindexuje, tak usoudí, že nejsou důležité).
To se teoreticky stát může – Google říká, že pokud je stránka dlouho noindex, bude ji crawler navštěvovat méně často. Ale u stránkování to nevadí; hlavní je, že se dostane aspoň někdy k odkazům na produkty přes stranu 1 a následování.
Moje doporučení 2025: Klidně pokračujte s noindex, follow u dalších stran. Alternativně lze zvážit stránkování řešit tzv. load more tlačítkem a mít jednu dlouhou stránku (to je ale z pohledu UX a měření komplikované). Nebo můžete nechat indexovat pár prvních stran a zbytek noindex – ale proč? Strana 2 či 3 typicky moc hodnoty navíc nenese.
Takže stále platí: indexujte hlavně stranu 1 a zbytek používejte jen na procházení. A nezapomeňte, že Seznam nic jako prev/next stále neumí, takže bez noindex by vám s chutí zaindexoval i stránky 2,3,… (Seznam budiž důvodem, proč určitě stránky 2+ noindexovat).
Ještě drobnost: pokud stránkování používá parametry v URL (?page=2 atd.), a vy jste kdysi definovali ty parametry v GSC Param tool, tak to už nefunguje (viz výše). Nechte to na Google – bude-li page param v URL, on to projde. Stránky noindexneš, takže cajk.
Filtrace (fasetová navigace)
Facetová navigace (filtrování) je další oříšek zejména u e-shopů. Ve 2018 radili: rozhodněte se, které filtry jsou důležité (mají hledanost, obsahový význam) a které ne. Pomůže k tomu klasifikační analýza klíčových frází (tedy zjistit, zda lidé hledají např. „černé košile s krátkým rukávem“ – pak by kombinace těch filtrů mohla dávat smysl jako vstupní stránka).
Důležité filtry
pro ty je ideální vymyslet indexovatelné řešení. Třeba vytvořit cílené landing page (kategorie) pro kombinace, které jsou pro byznys podstatné. Anebo povolit kombinovaný filtr s tím, že výsledná URL bude normálně crawlable, indexable a uvedená v sitemap.xml.
Důležité je, aby taková filtrovaná stránka měla unikátní obsah – aspoň nadpisy, texty upravené podle filtru, případně jiný výpis produktů. Např. filtr Značka: Samsung + Barva: černá – výsledná stránka by mohla mít titulek „Černé lednice Samsung – vše skladem…“ atd., aby byla relevantní pro dotaz „černé lednice Samsung“.
Pokud to takto nevyřešíte, hrozí, že se nedostanete do výsledků na dotazy typu „zelená košile XL“ apod. Uživatel pak takový long-tail nenajde.
Nedůležité filtry
Ty by naopak neměly generovat indexovatelné stránky. Např. filtrování podle dostupnosti (skladem/na objednávku), podle nějakých interních parametrů, co nikdo nehledá. Ty klidně řešte pomocí JS bez změny URL, nebo pokud URL vznikají, tak je blokujte či noindexujte. Nechcete stovky kombinací typu „seřadit dle ceny + skladem + 30 položek na stránku“ indexované.
Zlatá střední cesta je držet počet indexovaných kombinací při zemi. Kde to jde, použít jeden filtr na stránku a ostatní jen na klientu, nebo používat hierarchii (např. nejdřív kategorie = barva, a pak v rámci ní podfiltr značka – ale to už je v URL sdružené). To je hodně komplexní problematika, na kterou tu není prostor do detailu. Podstatné: filtrování může zavalit vyhledávač kvantem URL. Vaším úkolem je zajistit, že procházet se budou jen smysluplné a nekonečné kombinace se utlumí.
2018 zmínili příklady, kdo to má vyřešené dobře: Heureka, Glami, Bellarose. Tyto weby opravdu chytře pracují s filtry a tvoří z nich cílené vstupní stránky. Doporučuji se inspirovat.
Tip 2025: Pokud bojujete s obřími množstvími parametrických URL, zkuste analyzovat logy serveru (viz níže) – uvidíte, kam všude robot leze. Často objevíte tzv. crawl trap – třeba stránku, která generuje odkazy sama na sebe s různými parametry, a robot v tom bloudí. To je třeba řešit, jinak vám to sežere crawl budget. Někdy pomůže nasadit v robots.txt Disallow na určité vzory URL (např. všechny kombinace 3 a více filtrů). Jindy je třeba upravit front-end, aby takové odkazy vůbec nevznikaly.
Co se na kurzu probíralo dál?
Školení bylo opravdu nabité informacemi. Kdybych chtěla zmínit úplně vše, snad tenhle článek nikdy nedokončím 🙂 Proto už jen stručně vypíšu další témata, která padla – a přidám k nim současný pohled a tipy:
Automatizace textů
Toto téma řešilo, co dělat, když máte e-shop o tisících stránkách a potřebujete pro ně obsah (popisky kategorií, produktů). Texty lze částečně automatizovat.
V roce 2018 se tím myslelo využití šablon, doplňování dat do předpřipravených vět apod. Dnes je to ještě zajímavější: s nástupem AI generátorů (GPT-3.5/4, Bard apod.) se nabízí generovat texty strojově.
Google k tomu zaujal stanovisko v tom smyslu, že AI generovaný obsah není sám o sobě zakázaný, pokud je kvalitní a užitečný. Už to nebere jako automaticky spam (dříve byl striktně proti strojovému obsahu).
Pozor – kvalitní je klíčové slovo. Pokud pustíte AI, ať vám napíše 1000 produktových popisků a ani je nečtete, koledujete si o průšvih (můžou tam být faktické nesmysly, duplicity, balast). Ale lze AI využít s rozumem: nechat si vygenerovat draft a ten pak zeditovat lidsky. Tím ušetříte čas a získáte slušný výsledek.
Na školení tehdy asi tak daleko nebyli – spíš radili efektivní ruční postupy. Každopádně automatizace obsahu je dvousečná.
Doporučuji: automatizujte strukturu, data, klidně využijte AI pro návrh, ale vždy zajistěte, že finální text dává hlavu a patu a není duplicitní s jinými stránkami.
PS: Jo a nezapomeňte na překlady – i tam může AI pomoci jako prvotní návrh, ale lidská korektura je zatím nenahraditelná.
Vícejazyčné weby
U vícejazyčných stránek musíme řešit hreflang – tedy označení jazykových mutací, aby vyhledávače správně doručily českému uživateli českou verzi, angličanovi anglickou atd. Google umí do jisté míry rozpoznat jazyk sám, ale není to stoprocentní. Proto existuje atribut hreflang (v HTML hlavičce nebo v sitemap), kterým propojíte URL mezi jazyky.
Na školení padla zmínka, že Google někdy jazyk nepozná a proto tu hreflang je. Dodnes se nic lepšího nevymyslelo – hreflang je stále standard pro mezinárodní SEO. Co je nového? Snad jen to, že Google Search Console přidala report Mezinárodní cílení, kde vidíte chyby v hreflang (chybějící protějšky apod.). Určitě se držte osvědčených postupů:
Hreflang uvádět pro každou kombinaci jazyka a země, co máte (např. cs-cz, sk-sk… nebo prostě jen cs, sk).
X‑default anotaci přidat, pokud máte i nějakou výchozí (třeba globální anglickou stránku).
Každá stránka by měla odkazovat na všechny své mutace včetně sebe sama (self-referencing hreflang).
Vyhýbejte se chybám v kódech (GSC je odhalí).
Bing i Seznam myslím hreflang taky podporují, minimálně Bing určitě. U Seznamu kdysi Jarda říkal, že pro Seznam je nejlepší prostě mít zvlášť domény pro každou jazykovou verzi (cz, sk, pl…).
Takže závěr: hreflang stále používejte, žádná revoluce se tu nekonala. Google jen pořád opakuje – hreflang není o rankingu, jen o doručení správné verze správnému publiku. A funguje to dobře, když to nastavíte správně.
Strukturovaná data
Strukturovaná data popisují vyhledávačům strukturu informací na stránce. Pomocí schema.org značek můžeme sdělit, že určitý text je třeba název produktu, jiný text je cena, další je recenze apod.
Vyhledávače pak mohou tyto údaje využít k zobrazení bohatších výsledků (rich snippets) – třeba hvězdičkové hodnocení, cenu a dostupnost u produktu, události v kalendáři, drobečkovou navigaci, FAQ rozbalovací otázky atd.
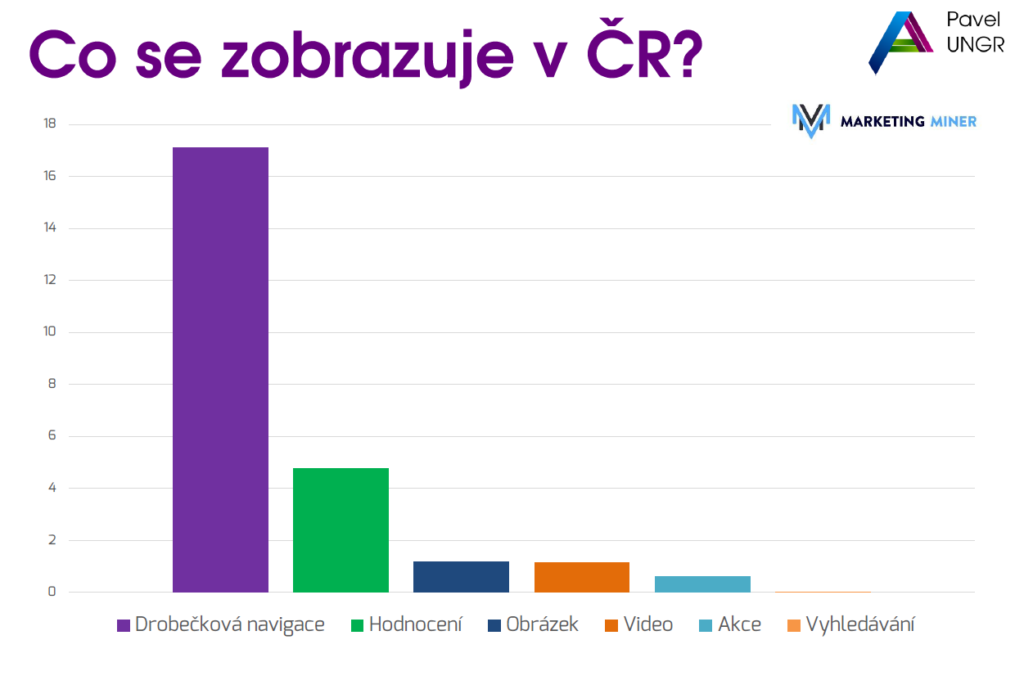
V ČR už v roce 2018 byly rich snippets poměrně běžné. Zmíněno bylo, co se v ČR zobrazuje – tehdy hlavně recenze (hvězdičky), recepty, produkty…
Dnes je spektrum podobné, ale přibyly třeba FAQ výpisy a How-to návody. Nutno říct, že Google v srpnu 2023 hodně omezil zobrazování FAQ a HowTo výsledků – zneužívalo to moc webů. Nyní FAQ rich výsledky ukazuje převážně jen u důvěryhodných webů (např. vládní či zdravotnické) a ostatním už ne.
How-to výsledky zase zobrazuje jen na desktopu, ne na mobilu. Takže pokud jste v roce 2022 hromadně nasazovali FAQ schema, možná jste zjistili, že od podzimu 2023 už se vám ty hezké rozbalovací otázky v SERPu neukazují. Není to chyba – je to záměr Google pro zkvalitnění SERPu.
Nicméně pořád platí, že strukturovaná data jsou užitečná. Správně nasazená schema markup mohou zvýšit proklikovost (CTR), protože výsledek je vizuálně bohatší a lákavější.
Navíc Google i další vyhledávače mohou data využít i jinak – třeba pro hlasové asistenty, nebo do budoucna pro trénink AI (kdo ví). Minimálně ale pro Google Search to dává smysl.
Novinky posledních let:
Google rozšířil podporu o Product schema – varianty produktů. Např. přidal možnost označit varianty pomocí ProductGroup a uvést různé varianty (velikost, barva) a jejich odlišné URL. Od 2023 to umí zobrazovat různé varianty v produktovém snippetu. Taky přidal zmíněné doprava a vrácení – shippingDetails a returnPolicy ke schema Product (od 2022/23), takže se ve výsledcích u e-shopu můžou ukazovat třeba info „Doprava zdarma nad 1000 Kč“ apod.
Video schema – přibyly třeba klipy (Clip markup) pro označení kapitol videa a Seek markup pro posouvání na čas ve videu.
Article schema – Google teď preferuje spíš používat to, co je nutné k funkcím (např. pro Google Zprávy NewsIndexing). Klasický Article je spíš pro pořádek.
Recipe, Event, JobPosting atd. – to vše stále funguje. JobPosting dokonce Google indexuje přednostně přes svůj Indexing API (to je jediný případ, kdy Google má vlastní API pro příjem dat – pro nabídky práce a pro Live Streamy).
JSON-LD vs mikrodata – dnes jednoznačně preferováno JSON-LD (JavaScriptový blok script s daty). Je to jednodušší na správu a Google to umí dobře. Mikrodata v HTML fungují taky, ale dělají nepořádek v kódu a hůř se to kontroluje.
Určitě doporučuji nasadit strukturovaná data tam, kde dává smysl: produkty, recepty, články (autor, logo, atd.), breadcrumbs, FAQ (pokud jste autorita, ještě vám je ukáže), how-to, video – cokoliv váš web má.
Jen dbejte na přesnost: data musí odpovídat tomu, co je skutečně na stránce vidět. Google tohle validuje a když zjistí nesoulad (např. ve schema řeknete, že produkt je „skladem“, ale na stránce je „Není skladem“), může udělit ruční opatření za nepravdivá strukturovaná data. Takže nelhat. 😇
Pro Seznam.cz – ten sice rich snippets moc nezobrazuje (jeho výsledky jsou střídmější), ale v roce 2020 spustil vlastní Seznam FAQ panel (SExA – Seznam Expert Answers), který bral data z mikrodotazů. Ale to je trošku jiný formát. Každopádně struktur. data neuškodí ani kvůli Seznamu, minimálně je ignoruje, v nejlepším případě využije.
Optimalizace obrázků
Nezapomeňme na obrázky – i ty hrají roli v SEO. Na školení zaznělo pár tipů: popisný název souboru, vyplněný atribut ALT (alternativní text), relevantní okolní text a případně i strukturovaná data pro obrázky (ImageObject schema) či jejich zahrnutí do image sitemap.
Obrázky dnes navíc Google používá nejen v Obrázkovém vyhledávání, ale i v některých rich výsledcích (např. u receptů nebo článků se může zobrazit thumbnail obrázku).
Aktuální tipy k obrázkům:
Používejte moderní formáty (WebP, AVIF) pro menší velikost – Google to doporučuje pro rychlost. Googlebot umí tyto formáty indexovat.
ALT texty pište smysluplně, jako popis obrázku. Pomáhá to i přístupnosti (screenreadery) a Google to bere v úvahu.
Lazy-loading obrázků – dnes běžná praxe. Jen pozor, ať se obrázek načte i pro Googlebota. Nejlepší je použít nativní loading=“lazy“ atribut, který je podporovaný a Googlebot s tím umí pracovat. Pokud máte vlastní lazy load skripty, ověřte v nástroji Mobile-Friendly Test nebo v Search Console (Inspekce URL → Zobrazit stránku) že se obrázky načtou. Googlebot může scrollovat omezeně, ale většinou načte aspoň vše, co je nastaveno přes Intersection Observer s threshold ~0.
OpenGraph/Twitter karty – to sice není pro vyhledávač, ale když už řešíte obrázky, nastavte si OG tagy pro hezké náhledy na soc. sítích.
Penalizace, její druhy a řešení
Téma penalizací nesmí chybět. Rozlišujeme manuální penalizace (ruční zásah od týmu vyhledávače) a algoritmické (automatické zhoršení kvůli algoritmu). Může to být globální penalizace (postihne celý web) nebo částečná (třeba jen sekci nebo skupinu stránek).
Jak je řešit? U manuálních Google poskytne v GSC zprávu a je třeba chybu napravit a požádat o přehodnocení (reconsideration). U algoritmických je to horší – tam žádná zpráva nepřijde, prostě spadnete ve výsledcích. Nezbývá než se snažit odhalit příčinu (často nekvalitní obsah, spamové odkazy, klamavé techniky) a zlepšit to. A čekat na další Core Update, jestli se to zvedne.
Co vyhledávačům vadí? V 2018 zmiňovali:
Obtěžující pop-upy (hlavně na mobilech – Google od 2017 penalizuje stránky, co zobrazují rušivé mezistránkové pop-upy hned po příchodu).
Neoriginální obsah (scraped, duplicitní).
Cloaking (jiný obsah pro bota a pro uživatele).
Skryté přesměrování (uživatel vidí něco, ale pak je skrytě přesměrován jinam – to Google nerad).
Skrytý text (text stejnou barvou, záměrné schovávání klíč. slov – jasný prohřešek).
Linkové podvody (tuny umělých odkazů, PBN atd. – to nepadlo, ale je to evergreen).
Zkrátka, nezkoušejte to ojebat – vyhledávače jsou chytřejší a hodně věcí odhalí. Dnes mají i AI systém (SpamBrain) na detekci spamu.
Pokud přeci jen k penalizaci dojde, nezoufejte a jednejte: identifikujte problém (proč by nás Google penalizoval?), opravte to, a pak buď požádejte o reconsideration (u manuální) nebo prostě čekejte a pokračujte v dobré práci (u algoritmické).
SEO a JavaScript
Část školení vedl Jarda Hlavinka a prý „to bylo maso“ – šlo o weby napsané v JavaScriptu a jejich indexaci. Už tehdy upozorňoval na věci jako AJAX Crawling, starý fragment #! v URL, nebo koncept server-side rendering (SSR).
V roce 2018 platilo, že Google umí JavaScript poměrně dobře renderovat, ale má to mouchy a hlavně to zdržuje indexaci (Googlebot nejdřív stáhne HTML, pak zařadí stránku do fronty na rendering, a teprve poté indexuje – dvoufázový proces). Jarda říkal, že by si uměl představit samostatné několikahodinové školení jen na tohle. A já souhlasím – je to kapitolka sama pro sebe.
Co nového k JavaScriptu v SEO? Google v roce 2019 přešel na „Evergreen“ Googlebota – což znamená, že jeho vykreslovací jádro (headless Chromium) se aktualizuje tak, aby vždy zhruba odpovídalo aktuální verzi Chromu.
Takže už neplatí, že by neuměl moderní ES6 věci – umí vše, co moderní prohlížeč. To spoustu problémů vyřešilo (už nepotřebujeme polyfill pro Promise atd.). Nicméně fyzikální limity zůstávají: renderování JS je náročné na výkon, takže Googlebot má omezený „render budget“. Stránky, které vyžadují hodně scriptů, mohou čekat déle na zařazení do indexu.
SSR vs. CSR: Dnes už je víceméně konsenzus, že pro lepší SEO (a vlastně i UX) by větší webové aplikace měly využívat Server-side rendering nebo aspoň hydration. Frameworky jako Next.js, Nuxt, SvelteKit apod. umožňují generovat HTML na serveru a na klienta posílat už připravený obsah, který se jen oživí. To je ideální – vyhledávač vidí kompletní HTML, indexuje hned, a JS pak třeba dotáhne interaktivitu.
Pokud máte Single Page Application bez SSR, tak aspoň zvažte dynamic rendering pro boty – např. nasadit nástroj jako Rendertron, Prerender.io, případně Cloudflare Workers pro vykreslení stránky pro user-agenta Googlebot (to už se dostáváme do oblasti Edge SEO, viz dále).
Za zmínku stojí, že se vžilo i to spojení „edge SEO“ – tedy dělat SEO úpravy na úrovni CDN edge pomocí serverless skriptů. Tím se dá třeba naservírovat předrenderovaný HTML obsah robotovi, i když uživateli posíláte JS aplikaci.
Tohle je docela šikovné, a právě serverless rendering uleví vašemu serveru (vše běží na CDN) a zrychlí to. Navíc to umožní dělat technické zásahy bez změny kódu webu (např. vložit kanonické linky, upravit head tagy apod. on-the-fly). Tyhle postupy už ale vyžadují hodně technické zdatnosti – spíše pro enterprise weby.
Každopádně, pokud vás trápí SEO u JS heavy webu, obraťte se na odborníka (Jarda se tomu stále věnuje). Je to komplexní, ale řešitelné. A pamatujte, co platilo i tehdy: Pokud to jde, neblbněte s JavaScriptem. Tedy – nepotřebujete-li nutně SPA, udělejte klasický web. Nebo aspoň použijte hybridní framework. Usnadníte si SEO život.
Access logy
Proč je vhled do access logů důležitý? Logy webového serveru vám ukážou veškerý provoz – tedy i všechny návštěvy robotů. Analýzou logů zjistíte, které stránky Googlebot (či SeznamBot) navštěvuje jak často, kde naráží na chyby, kam zbytečně leze atd. Na školení radili v logách hledat chyby 4xx a 5xx, také přesměrování, a prostě srovnávat, co byste čekali vs. co robot dělá.
Padlo tam, že někdy zjistíte z logů víc než z nástrojů typu Xenu, Screaming Frog nebo z klasických analýz. Je to pravda – logy jsou skutečnost, ne simulace. Vidíte reálné chování crawlerů.
Já dodám: v roce 2018 tohle nebylo zdaleka mainstream, dnes už je log analysis běžnou součástí technického SEO auditu větších webů. Existují nástroje, které vám logy zpracují (např. Screaming Frog má Log File Analyser, jsou cloudové služby jako OnCrawl, Botify, nebo prostě Elastic Stack – Kibana + Elasticsearch).
Klíčové je pohlídat:
Neplýtváte crawl budgetem? Tj. nelezou boti pořád dokola na nějaké nekonečné parametry, smyčky? (Viz facety výše.)
Nejsou někde masové chyby? Třeba odkazuje web na URL, co vrací 404 – a bot tam chodí a nic. Nebo 500 chyby.
Priority stránek: Z logu lze poznat, jestli Google chodí často na důležité stránky (domovka, kategorie) – měl by. Pokud ne, něco je špatně (možná je nenachází nebo je považuje za nezajímavé).
Nové vs staré URL: Když něco přesměrujete, sledujte, jestli bot stále nezkouší staré URL (měl by postupně přestat).
Na školení zazněla rada: kdybyste se ztratili v příkazové řádce při analýze logů, obraťte se na Pavla, Jardu, nebo Filipa Podstavce 🙂 (Filip měl přednášku na SEOlogeru 2017 právě o logfile analysis). Ale to bohužel nevím, jak je dnes platné 🙂
Za mě – mrkněte do logů aspoň jednou. I když nejste programátor, není to tak složité. A může vám to otevřít oči (já třeba jednou objevila, že nám každý den v noci Googlebot prochází tisíce URL s parametrem &order=, které byly zbytečné – nasadili jsme noindex a bylo po problému).
Mimochodem, v roce 2023 se řeší i logy vs. AI boty – jak jsem psala, AI crawleři jsou noví hráči. Podle některých reportů už dělají přes významnou část návštěvnosti.
Takže v logu možná uvidíte GPTBot, různá data-mining boty atd. Rozhodně stojí za to si sepsat robots.txt pravidla i pro tyto boty. OpenAI třeba umožňuje přes robots.txt zakázat GPTBot (a tím obsah nechat vynechat z tréninku modelů). Je to na zvážení – někdo chce být součástí AI světa, někdo radši ne.
Page speed (Rychlost webu)
Souhlasím s větou z prezentace:
„Kvůli SEO vyřešte základ, kvůli lidem zrychlujte co to jde.“
Rychlost načítání stránky je totiž jednak ranking faktor (byť malý), ale hlavně ovlivňuje uživatelskou spokojenost a konverze. Studie ukazují, že i zlepšení o 0,1 sekundy může zvýšit konverzní míru o 8–10 %. To je dost, nemyslíte?
Pro základní přehled rychlosti v roce 2018 jsem používala nástroje jako Marketing Miner (modul měření rychlosti) nebo Google PageSpeed Insights.
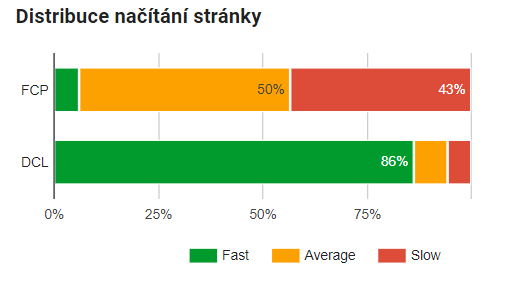
V tom roce (2018) došlo k velké změně – PageSpeed Insights začal používat reálná data z prohlížeče Chrome a ukazoval tzv. distribuci načítání (kolik procent načtení je rychlých, průměrných, pomalých). To byl vlastně předvoj dnešních Core Web Vitals.
Od té doby Google definoval Core Web Vitals – tři hlavní metriky webové pohody:
LCP (Largest Contentful Paint) – kdy se načte hlavní obsah,
FID (First Input Delay) – doba reakce na první interakci,
Tyto signály se v květnu 2021 staly oficiálně drobným ranking faktorem (tzv. Page Experience update).
V roce 2024 pak Google metriku FID nahradil novou robustnější metrikou INP (Interaction to Next Paint). INP lépe hodnotí celkovou odezvu stránky na vstupy uživatele (nejen první interakci). Od března 2024 tedy Core Web Vitals tvoří LCP, CLS a INP.
Dnešní PageSpeed Insights i Search Console už reportují INP místo FID. Doporučené thresholdy zůstaly: „dobré“ LCP je < 2,5 s, dobré CLS < 0,1, a pro INP se jako dobrý považuje < 200 ms (v 75. percentilu). Google přímo uvádí, že TTFB (Time To First Byte) by měl být do 0,8, protože pak se stíhá FCP v limitu.
TTFB nad 1,8 s považuje za špatný. Takže rychlý server je základ – ostatně pomalý hosting může brzdit jak Googlebota (crawl rate), tak uživatele. Pokud máte podezření, otestujte si hostování (Maxiorel měl pěkný test hostingu, viz odkaz v původním článku).
Dnes k měření rychlosti používám kombinaci:
PageSpeed Insights (rychlá kontrola + data z CrUX),
WebPageTest (podrobnější test, možnost simulovat různé sítě, prozkoumat waterfall),
Lighthouse (to je součást dev tools, nebo přes PageSpeed web).
Chrome DevTools – pro ladění přímo v prohlížeči.
Případně služby jako GTmetrix pro klientské reporty.
Z hlediska SEO stačí dostat se do „zelených“ hodnot Core Web Vitals, pak už máte klid (ranking boost je buď žádný, nebo jen že nedostanete drobný hendikep pokud by to bylo špatné). Ale z hlediska byznysu platí – čím rychleji, tím lépe. Amazon kdysi říkal, že každých 100 ms zpoždění je znát na tržbách.
Na školení zaznělo trefně:
„Kvůli SEO stačí vyřešit ten základ, kvůli lidem zrychlujte dál.“
Podepisuji. Nejde jen o čísla, jde o to, že uživatel se rád vrátí na web, který je svižný. A vyhledávače to vnímají nepřímo skrze spokojenost uživatelů.
Ještě dodatek: v roce 2024 Google sice ruší samostatný Page Experience report v GSC, ale Core Web Vitals report tam nechává. Tak se nelekněte, až to zmizí z menu – oni to jen konsolidují.
Distribuce načítání stránky v PageSpeed Insights
Někdy může být na vině pomalý hosting. Prověřte webhosting nebo server po stránce výkonu. Několik testování hostingů najdete v článku Jak otestovat rychlost a výkon hostingu.
„Dobrý webhosting = základ pre rýchly web. WebSupport je podľa mňa najlepší slovenský hosting v pomere cena/kvalita.“
Roland Vojkovský
Přechod z HTTP na HTTPS, redesign a nová doména
Na závěr kurzu v 2018 jsme probrali ještě velké změny webu jako přechod na HTTPS, celkový redesign webu nebo převod na novou doménu. To všechno jsou zásadní zásahy a je potřeba je pečlivě naplánovat. Doporučovali si nejdřív přečíst Jardův článek „Co si pohlídat při přechodu na HTTPS“ – ten byl (a je) skvělý checklist.
V roce 2025 už je HTTPS naprostý standard. Pokud váš web ještě není na HTTPS, tak to napravte ihned. Pro Google je to drobný ranking faktor už od 2014, ale hlavně moderní prohlížeče označují HTTP weby za „nezabezpečené“. Navíc spousta nových web API funguje jen na HTTPS (geolokace, Service Workers atd.). Čili tady není o čem.
Přechod na HTTPS je vlastně přesměrování celého webu na nové URL (s https). Dnes je to jednodušší než kdysi – Let’s Encrypt certifikáty zdarma, hostingy to umí jedním klikem.
Jen nezapomeňte na drobnosti: přesměrovat všechny varianty (http://, http://www, https://www) konzistentně na https://domena, upravit všechny interní odkazy a resource URL na https, přidat novou verzi webu do Search Console (protože to je jiný protokol), případně nasadit HSTS header. Ale to už zabíhám.
Redesign webu – tady je obrovský prostor nasekat chyby. Při redesignu často vznikají nové URL (změní se struktura), nebo se maže obsah, mění se vnitřní linkování, atd.
Rozhodně přizvěte SEO konzultanta do procesu redesignu, ideálně už do fáze návrhu URL struktury. A pak před spuštěním překontrolovat, že se neztratily důležité texty, že title a meta description jsou na novém webu alespoň tak dobré jako staré, že stránky mají buď stejná URL nebo jsou nachystané redirecty ze starých na nové. Není nic horšího než „nahodíme nový web a půlka URL hází 404“. Tím přijdete o pozice i návštěvy.
Nová doména – to je podobné, vynásobeno tím, že přicházíte o veškerou značkovou historii. Google sice přenese většinu signálů přes 301 redirecty, ale může to trvat. Určitě nahlaste změnu domény v GSC (funkce Změna adresy). Sledujte pozice, logy, a počítejte, že to může kolísat pár měsíců. Když to uděláte pečlivě (1:1 redirecty všech starých stránek na nové odpovídající), většinou se to spraví. Pomoci může i dočasně zvýšit rozpočet na brand PPC, ať jste vidět, když by SEO haprovalo. Zkrátka, jak říkám: při těchto velkých změnách “nezapomeňte mít u sebe schopného SEO konzultanta“. Byla by škoda přijít o viditelnost a těžce vydobyté pozice kvůli opomenutí.
Za školení díky
Školení v roce 2018 bylo super a dodnes z něj těžím. Pokud budete mít někdy možnost se na podobné dostat, neváhejte. Pánové Ungr i Hlavinka (a samozřejmě mnozí další v oboru) rádi poradí – často jsou aktivní i ve FB skupinách jako SEOloger: Veřejná diskuze o SEO CZ / SK apod.).
A co dodat závěrem? Technické SEO není všechno, ale je to základ, bez kterého se neobejdete. Navíc je to aspekt, který máte skutečně ve svých rukou. Když ho podceníte, nepomůže vám sebelepší obsah, protože se k uživatelům nedostane. Naopak dobře zvládnuté technické SEO může dát vašemu webu náskok – vyhledávače ho projdou snáz, indexují rychleji, uživatelé budou spokojenější díky rychlosti a použitelnosti.
SEO v roce 2025 je zase o něco složitější disciplína než v roce 2018. Ale pevné základy platí. Indexace, crawling, obsah, odkazy, rychlost – to všechno zůstává klíčové. Jen k tomu přibyly nové kapitoly jako Core Web Vitals, AI, a neustále se měnící SERP features. Doufám, že tenhle aktualizovaný průvodce vám pomůže se v tom vyznat a připomene, na co nezapomenout.
Držím palce, ať se vašim webům v Google, Seznamu (i Bingovi a jinde) daří! 🚀
Pár článků k technickému SEO
IndexNow v roce 2025:Pěkné shrnutí principů a dopadu IndexNow (v angličtině). Data o adopci: 60 mil. webů, 17 % nových URL na Bingu. (A ano, Seznam.cz je v partě podporující IndexNow.)
Edge SEO a serverless rendering:Co to je a proč záleží – článek Al_sefati. Zajímavosti: AI boti už tvoří možná polovinu trafficu, zrychlení načítání o 0,1 s = +8 % konverzí.
Google Indexing & Crawling: Oficiální dokumentace Google k crawlování (developers.google.com) a blogpost o ukončení URL Parametrů.
Mobilní indexace a skrytý obsah: SEJ článek s vyjádřením Googlerů – skryté na mobilu = OK, bere se s plnou vahou.
Robots vs. Noindex: Připomenutí od Honzy Tichého (blog.medio.cz) a zpráva o zrušení podpory noindex v robots.txt.
Pavel Ungr & Jarda Hlavinka: Sledujte jejich blogy (pavelungr.cz, jakdelatseo.cz) pro další tipy. Zejména Jarda občas píše o JS SEO, Pavel o všem možném v SEO 🙂.
Ano. Zatímco algoritmy se mění, technické SEO zůstává jednou z mála oblastí, kterou máme plně pod kontrolou. Ovlivňuje, jak rychle a dobře vyhledávače web projdou, indexují a zobrazí uživatelům. Bez dobře zvládnutého technického základu se i kvalitní obsah ztrácí.
Jaký je rozdíl mezi robots.txt a noindex?
robots.txt slouží k řízení procházení – říká robotům, kam nemají chodit. Naproti tomu noindex zakazuje indexaci – stránku mohou roboti projít, ale nemají ji zařadit do výsledků vyhledávání. Důležité je, že když stránku zakážeš v robots.txt, robot se k ní nedostane, a tudíž ani nezjistí, že má být noindex.
Co dělat s filtrací a stránkováním v e-shopech?
U důležitých filtrů (např. „černé boty Nike“) můžeš vytvořit indexovatelné landing page s unikátním obsahem. Naopak méně důležité kombinace filtrů by měly být noindex nebo vůbec negenerovat nové URL. Stránkování řeš pomocí noindex, follow na stránkách 2 a dále – ať se neindexují, ale přenášejí odkazový signál.
Má smysl používat strukturovaná data (schema.org)?
Rozhodně ano. Správně nasazená strukturovaná data pomáhají vyhledávačům lépe pochopit obsah stránky a mohou zvýšit viditelnost ve výsledcích vyhledávání (např. pomocí rich snippets). I když Google některé typy snippetů omezuje, stále je to doporučená praxe.
Co je IndexNow a proč o něm uvažovat?
IndexNow je protokol, kterým můžeš aktivně vyhledávačům říct, že se na webu něco změnilo (např. nová stránka, aktualizace). Podporuje ho Bing, Seznam a další. Funguje rychle a doplňuje sitemapu. Pro Google zatím nefunguje, ale pro ostatní může urychlit indexaci důležitých změn.
Co jsem si odnesla z workshopu „Začněte využívat ChatGPT&spol naplno“ Davida Grudla? V květnu 2025 jsem se znovu zúčastnila workshopu o umělé inteligenci. Tentokrát jsme…
AI Overviews (v češtině Google uvádí jako „Přehledy od AI“) jsou novou funkcí ve výsledcích vyhledávání Google, která pomocí generativní umělé inteligence přímo na stránce…
Dobře strukturovaný obsah dnes rozhoduje o tom, jestli vás vůbec AI modely použijí jako zdroj. Nejde přitom o klasický SERP, ale o tzv. generované odpovědi.…
Když je dobrý developer, tak technické SEO určitě není překážkou, ale může být docela dobrou konkurenční výhodou 🙂
Spravovat souhlas s cookies
Abychom vám mohli poskytovat co nejlepší služby, používáme k ukládání a/nebo přístupu k informacím o vašem zařízení technologie, jako jsou soubory cookie. Souhlas s těmito technologiemi nám umožňuje zpracovávat údaje, jako je chování při prohlížení nebo jedinečné ID na těchto stránkách. Neudělení souhlasu nebo jeho odvolání může negativně ovlivnit některé funkce a vlastnosti.
Funkční
Vždy aktivní
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Předvolby
Technické uložení nebo přístup je nezbytný pro legitimní účel ukládání preferencí, které nejsou požadovány odběratelem nebo uživatelem.
Statistiky
The technical storage or access that is used exclusively for statistical purposes.Technické uložení nebo přístup, který se používá výhradně pro anonymní statistické účely. Bez předvolání, dobrovolného plnění ze strany vašeho Poskytovatele internetových služeb nebo dalších záznamů od třetí strany nelze informace, uložené nebo získané pouze pro tento účel, obvykle použít k vaší identifikaci.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.








")
Když je dobrý developer, tak technické SEO určitě není překážkou, ale může být docela dobrou konkurenční výhodou 🙂